
Express.js 的黑歷史及 Express 未來
4/5 更新, 根據讀者回饋,目前 IBM 已將 Express 及相關所有權轉移到 Node.js 基金會手中,讓 Node.js 社群能夠投入資源。https://nodejs.org/en/blog/announcements/foundation-express-news/
Express.js (以下簡稱為 Express)相信如果有在開發 node.js 程式的人肯定不陌生,幾乎是開發 Web 應用上手的第一堂課程,而 Express 至今已經四年左右的時間,幾乎是從 Node.js 0.4 版本時期就開始有(憑藉著印象,如果有錯請大家指正),當然這當中必定要讚嘆一下,神人 - TJ (拱手作揖)。
而在 Node.js 與 io.js 的戰爭時期, TJ 也宣布將 express 釋出,最後是轉換到 StrongLoop 公司底下,全權交給 StrongLoop (包含網域名稱, Express.js 以及 github reps 的所有權),當然這中間 TJ 肯定有協調些什麼,以及與其他 contributor 。
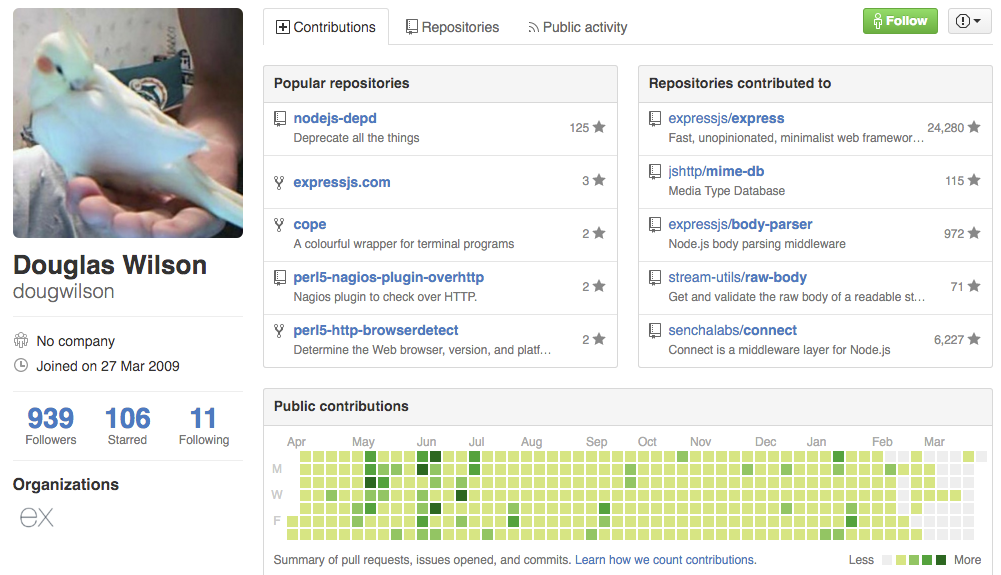
使用 Express 不可不知的人物, Douglas Wilson ,他是在 TJ 離開 Express 幾乎所有 reivew, issue, merge 都會經過 Doug 的手中
但是燃火線在於 Express.js 4 -> 5 的這段時間, StrongLoop 被 IBM 買走,但是也因為 Express 是一個很龐大的生態系統,以及對於 node.js web 開發是一個影響許多的 open source project ,而在這段時間中, Douglas Wilson 因為某些事情憤而離開 Express 組織中。

這才真正引爆了大家對於 StrongLoop, 及 IBM 的不滿。
黑歷史重點回顧
- TJ 將 Express 名字及所有內容轉移到 StrongLoop
- StrongLoop 並沒有指定或者對於 Express 有任何大量持續性維護
- 只有 Douglas Wilson 及其他志願者持續維持整個 Express 專案的進度
- StrongLoop 在這之後宣稱自己有所有權管理 Express ,但實際上沒有任何作為
- StrongLoop 被 IBM 收購
- 收購後, IBM 連同 StrongLoop 持續沒有任何作為
當然這嚴重的影響到 Express5 的發展,也的確開始走向當時的 io.js & node.js 的分裂狀況,為了避免這狀況再度發生,幾乎很多 node.js web 開發的大大都進入到 express issue 當和事佬(?)當然這當中還是要讚揚一下 Doug 的持續支持才有辦法成就 Express 到現在。
後續發展
進度還是持續中,不過很緩慢,但是在 issue 裡面,看的出來 IBM 也知道事情的嚴重性,稍微派了一些開發者進入到 Express 中開始投入資源進行開發。目前 IBM 已經將 express.js 整個專案及相關所有權轉移到 node foundation,全權由 Node 基金會投入人力,資源進行維護,開發的工作。
但是身為一個旁觀者,我必須說,這就是『自我願意』,和『不願意』的差別。
後記
軟體開發就是人為的藝術。我們雖然口口聲聲都說自己是在對著電腦進行溝通,但只要產品牽扯到團隊,營運,推廣,勢必就會有人的問題發生。對於開發技術來說真的是有趣的一件事情,不論今天是 inhouse 或者是 open source 的專案,只要扯到人,就會開始有許多問題。
文中省略了 TJ 將 Express 整包轉讓的議題,畢竟很多人是認為 open source 是神聖不可侵犯的,但實際上 open source 專案要持續營運下去,都是靠著小部分的人持續努力貢獻著,最後如果要專心將這個模組做完整還是要靠錢與資源下去運轉,勢必後期的長期維運,需要仰賴公司支撐,或者是金援才有辦法持續茁壯,這是一件很現實的事情,這蠻值得思考的。
帶出幾個有趣的議題?
- Express 的未來到底會如何? 是否有潛在的商業技術問題?
- 身為 node.js 開發者,我們是否該轉向,捨棄 Express, 朝向 hapi / Koa2 的懷抱?
- open source 到底是不是一個好的 business ?
留言
張貼留言